PaLM (Pathways Language Model) es un modelo de lenguaje grande basado en un transformador de 540 mil millones de parámetros desarrollado por Google AI.[1] Los investigadores también entrenaron versiones más pequeñas de PaLM, modelos de 8 y 62 mil millones de parámetros, para probar los efectos de la escala del modelo.[2]
PaLM es capaz de realizar una amplia gama de tareas, incluido el razonamiento de sentido común, el razonamiento aritmético, la explicación de chistes, la generación de código y la traducción.[2][3][4][5] Cuando se combina con indicaciones de cadena de pensamiento, PaLM logró un rendimiento significativamente mejor en conjuntos de datos que requieren razonamiento de varios pasos, como problemas verbales y preguntas basadas en lógica.[1][2]
El modelo se anunció por primera vez en abril de 2022 y permaneció privado hasta marzo de 2023, cuando Google lanzó una API para PaLM y varias otras tecnologías.[6] La API estará disponible primero para un número limitado de desarrolladores que se unan a una lista de espera antes de abrirse al público.[7]
Google y DeepMind desarrollaron una versión de PaLM 540B llamada Med-PaLM que se ajusta con precisión a los datos médicos y supera a los modelos anteriores en los puntos de referencia de respuesta a preguntas médicas.[8] Med-PaLM fue el primero en obtener una calificación aprobatoria en las preguntas sobre licencias médicas de los Estados Unidos y, además de responder con precisión tanto a las preguntas abiertas como de opción múltiple, también brinda razonamiento y puede evaluar sus propias respuestas.[9]
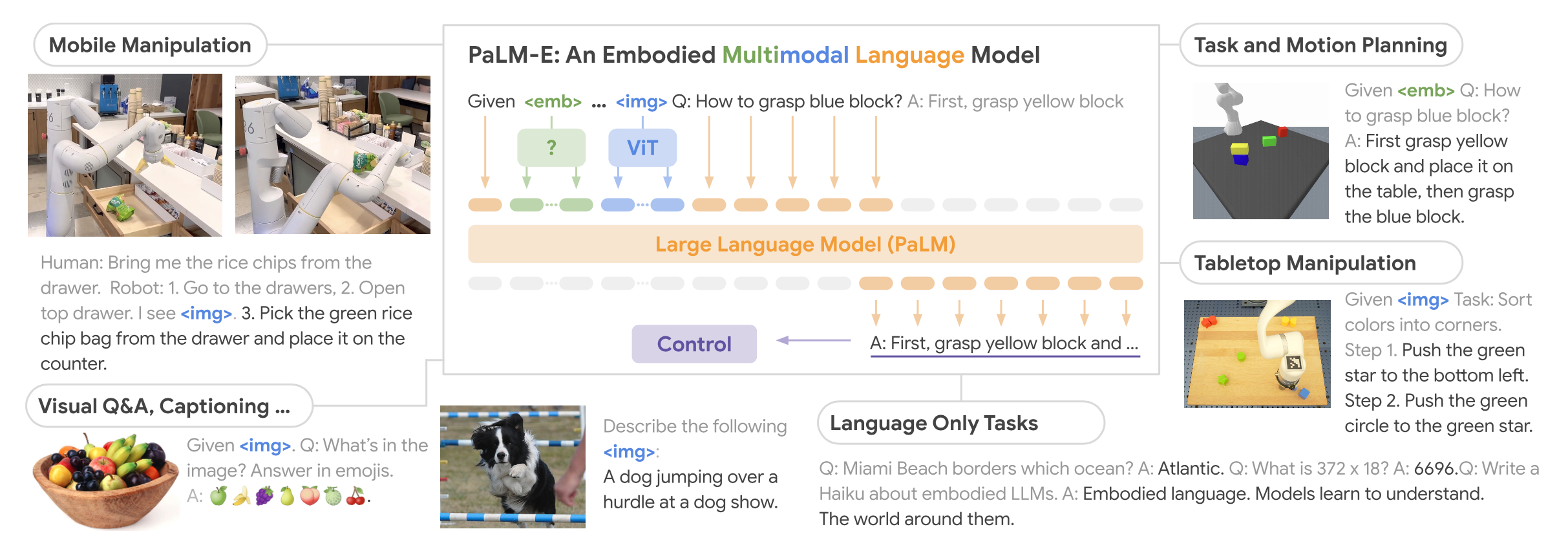
Google también amplió PaLM usando un transformador de visión para crear PaLM-E, un modelo de lenguaje de visión de última generación que se puede usar para la manipulación robótica.[10] El modelo puede realizar tareas en robótica de manera competitiva sin necesidad de volver a capacitarse o ajustarse.[11]
En mayo de 2023, Google anunció PaLM 2 en el discurso de apertura anual de Google I/O.[12] Se informa que PaLM 2 es un modelo de 340 mil millones de parámetros entrenado en 3,6 billones de tokens.[13]
En junio de 2023, Google anunció AudioPaLM para la traducción de voz a voz, que utiliza la arquitectura y la inicialización de PaLM-2.[14]
Capacitación
PaLM está preentrenado en un corpus de alta calidad de 780 mil millones de tokens que comprenden varias tareas de lenguaje natural y casos de uso. Este conjunto de datos incluye páginas web filtradas, libros, artículos de Wikipedia, artículos de noticias, código fuente obtenido de repositorios de código abierto en GitHub y conversaciones en redes sociales.[1][2] Se basa en el conjunto de datos utilizado para entrenar el modelo LaMDA de Google. La porción de conversación de las redes sociales del conjunto de datos constituye el 50 % del corpus, lo que ayuda al modelo en sus capacidades de conversación.[2]
PaLM 540B se entrenó en dos pods TPU v4 con 3072 chips TPU v4 en cada pod conectados a 768 hosts, conectados mediante una combinación de modelo y paralelismo de datos, que es la configuración de TPU más grande descrita hasta la fecha.[15] Esto permitió una capacitación eficiente a escala, utilizando 6144 chips, y marcó un récord de la mayor eficiencia de capacitación lograda para LLM a esta escala: una utilización de FLOP de hardware del 57,8 %.[2]
Referencias
Enlaces externos